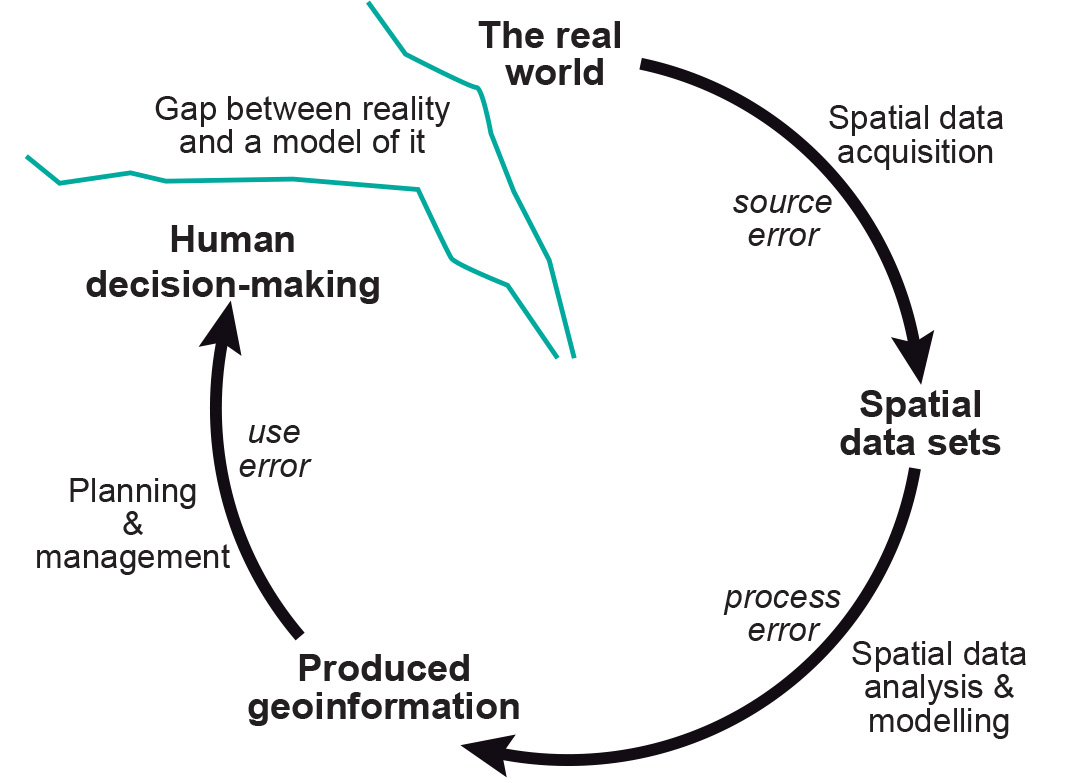
Uncertainty
Arises from our inability to measure phenomena perfectly and flaws in our conceptual models.
- Data quality: Instrument limitations, sampling costs, etc.
- Generalizations when representing phenomena: i.e., Bonini’s Paradox
- Incomplete knowledge, misunderstandings, biases, etc.
Data Quality
There is no standardized measure of data quality in GIS.
- Flaws may pass through many users before discovery.
- Must trust the data was collected and processed correctly.
- Risk of the users misinterpreting valid products.

In baking mistakes are obvious. Often in GIS, they are not.
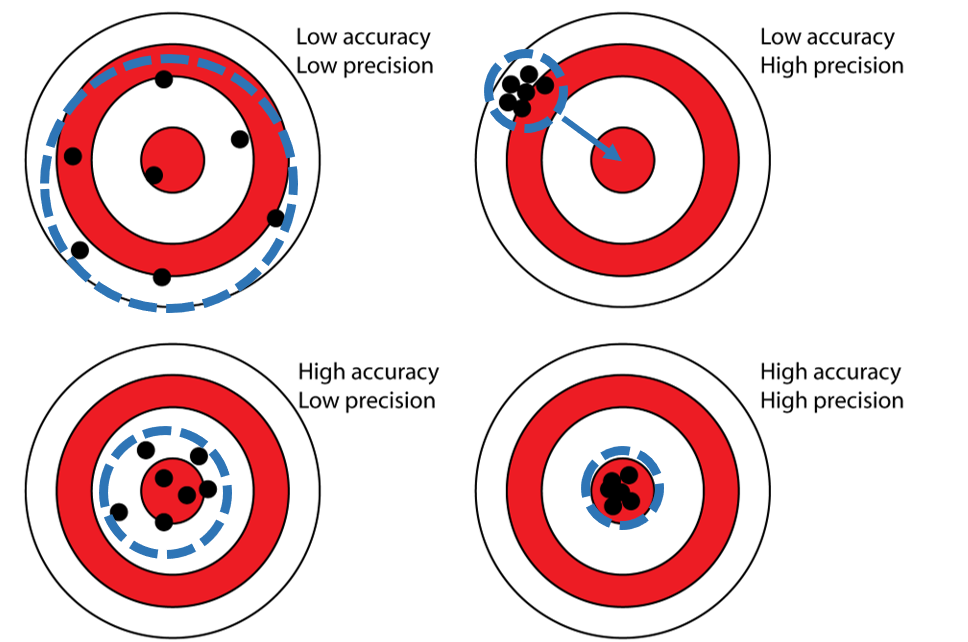
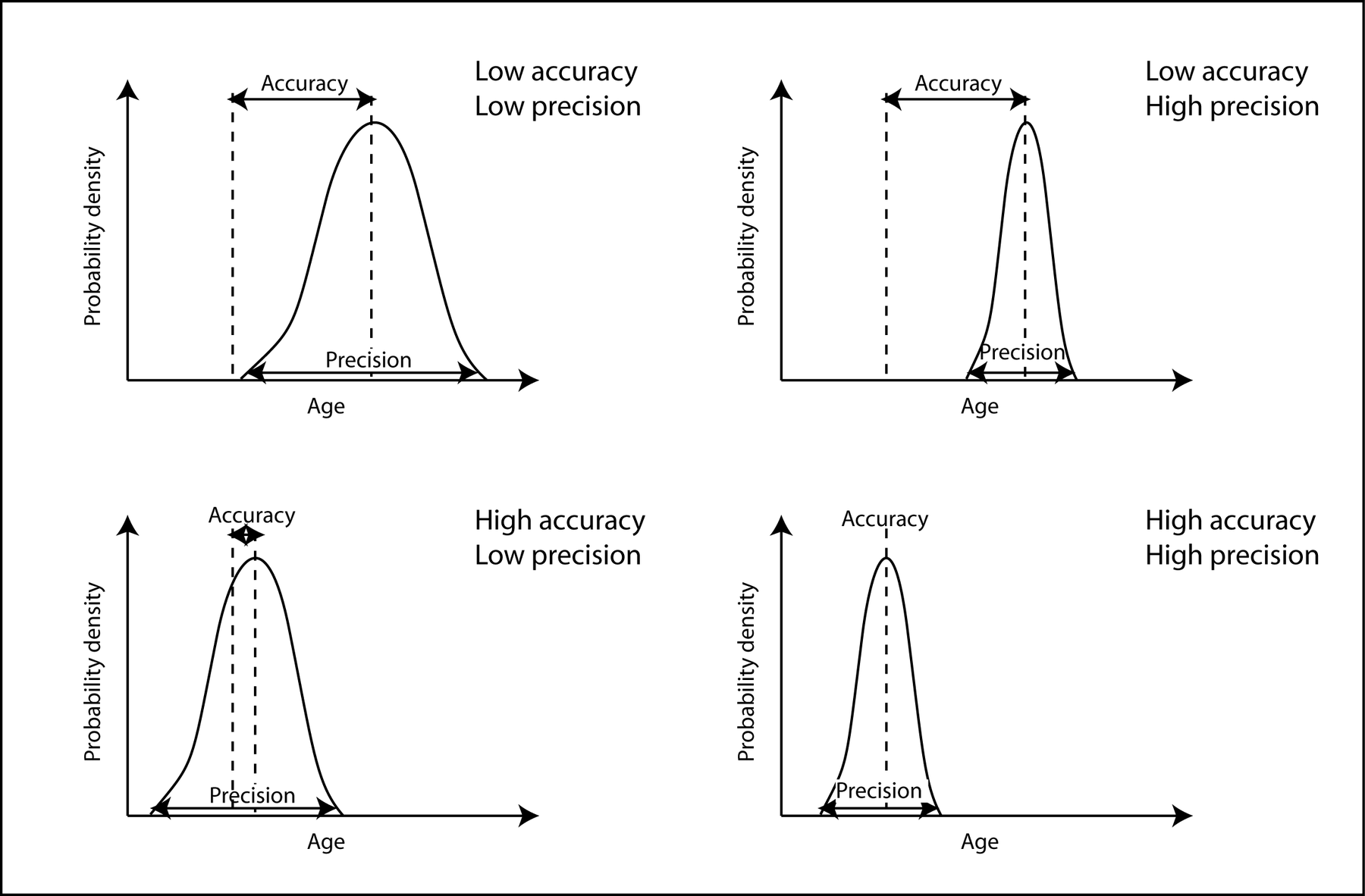
Error: Accuracy & Precision
- Accuracy: A systematic offset from the real world value
- Errors are biased
- Precision: A random offset from the real world value
- Errors are unbiased
Quantifying Error
Statistical methods can be used to describe uncertainty.
Quantify the offset (bias) and dispersion (unbiased) of data points.
Won’t tell us if we are correct with 100% certainty, but they can give us some insight.
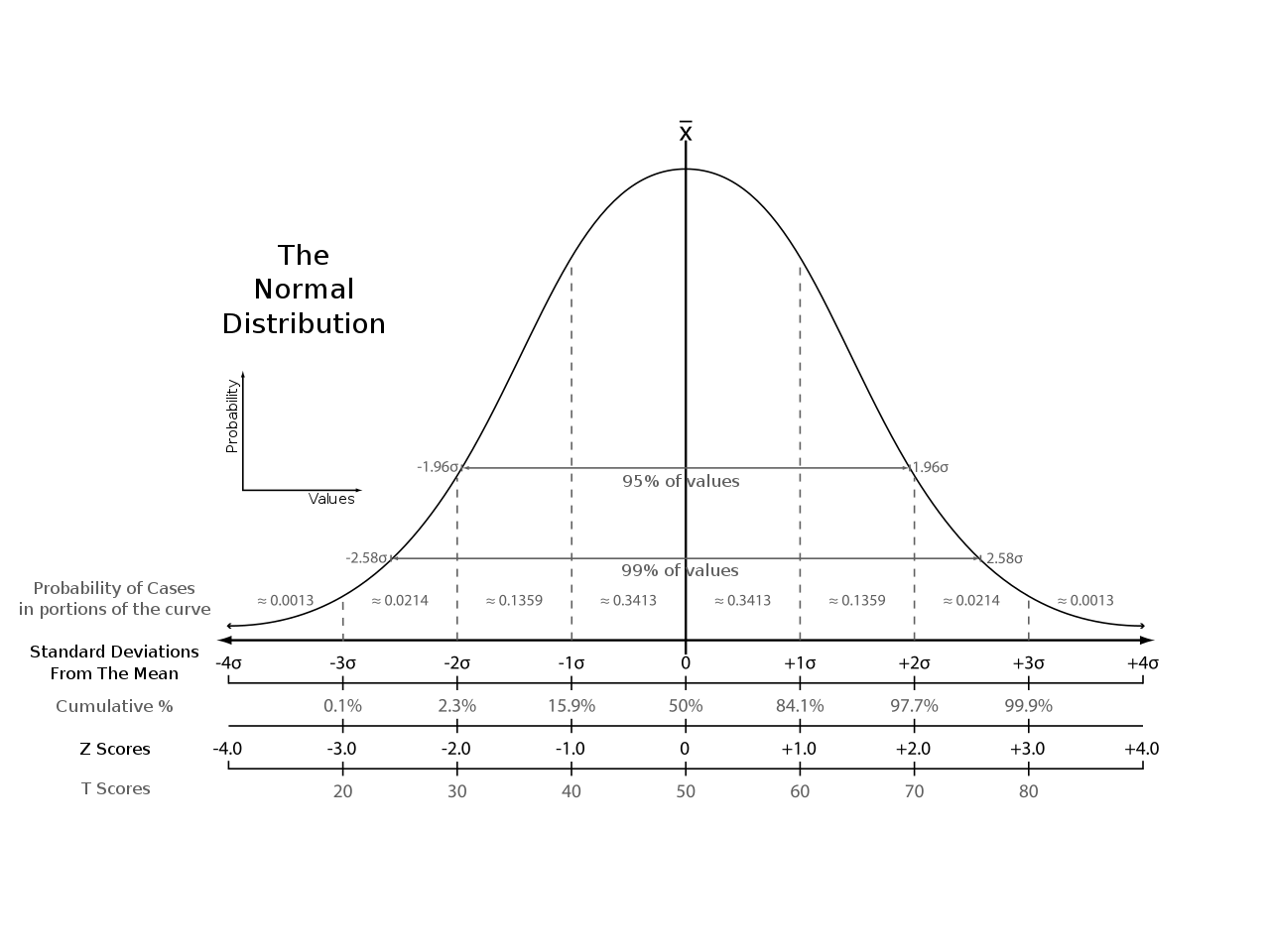
Quantifying Precision
Confidence Intervals (CI) can be used to specify a confidence level (i.e., 90%, 95%, etc):
- For Normally Distributed data:
- Typically presented as a range around the mean.
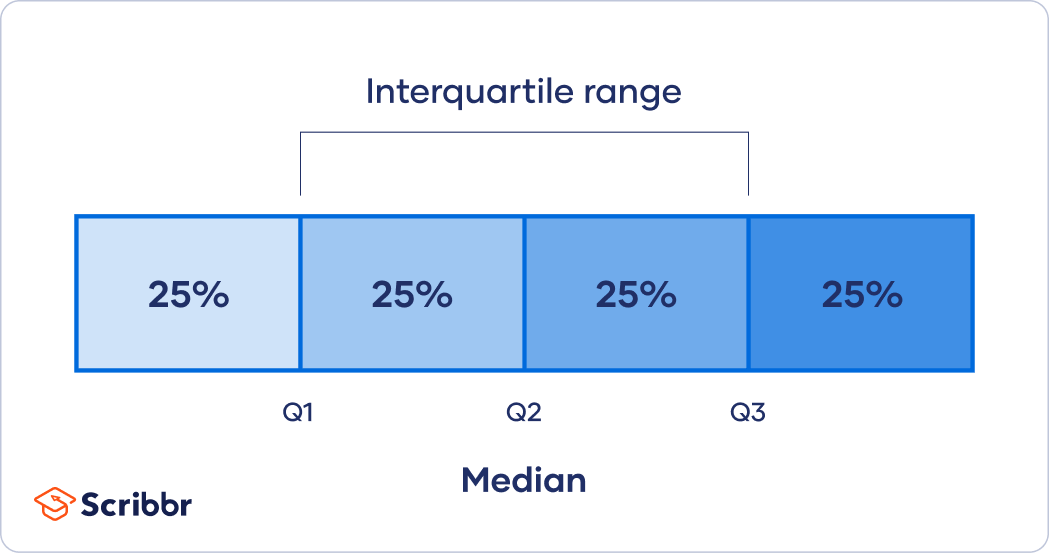
Quantifying Precision
Inter Quartile Range (IQR):
- For Non-normally Distributed data:
- Cannot be used to specify a confidence level.
- But it can give us some idea of the dispersion in a dataset.
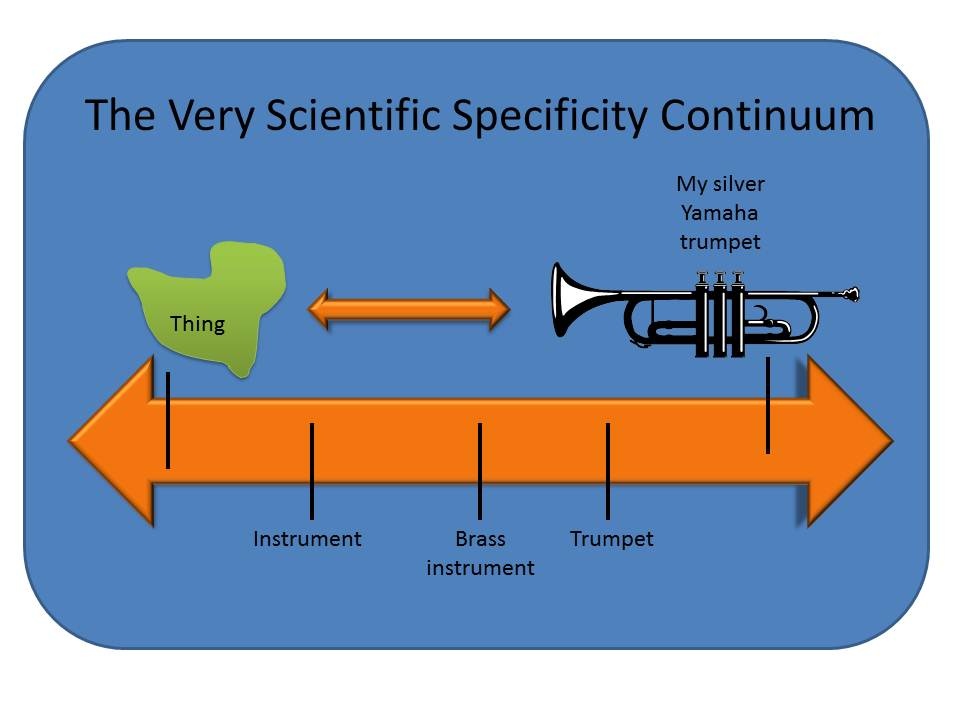
Vagueness
- What does “London” refer to:
- London, UK?
- London, Ontario?
- London Drugs?
- The word “bank”:
- A financial institution?
- The edge of a river?
Ambiguity
- Interpretation requires context.
- Where does a forest end and a grassland begin?
- The position of objects are unclear or changeable.
- Coastal boundary file - High tide? Low tide? Mean water level?

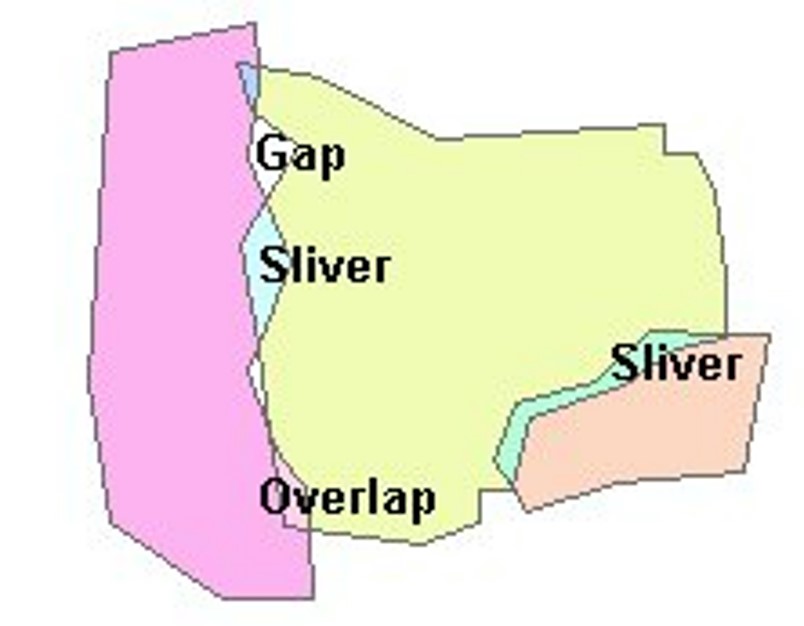
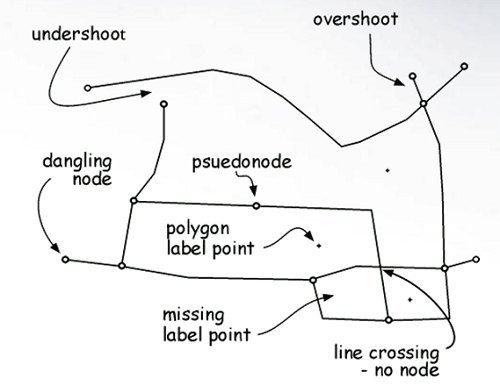
Digitization Errors
Errors that arise when creating vector features:
- Slivers: a feature is created between two features when it should not be.
- Gaps: there should be a feature, but there is not.
- Overlaps: one polygon sits over another polygon.
Digitization Errors
Errors that arise when creating vector features:
- Under/overshoots: vertex misses a connection.
- Extra nodes: unnecessary vertices.
- Missing features: features or attributes missing.
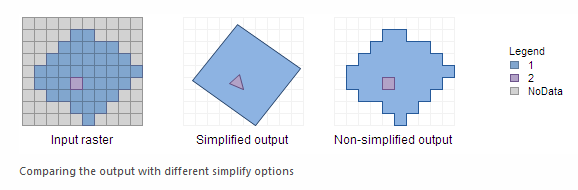
Conversion and Processing
Even with “perfect” data; GIS operations add uncertainty:
- Re-projecting to different coordinate systems
- Converting between data types
- Perform generalizations (i.e. data classification)
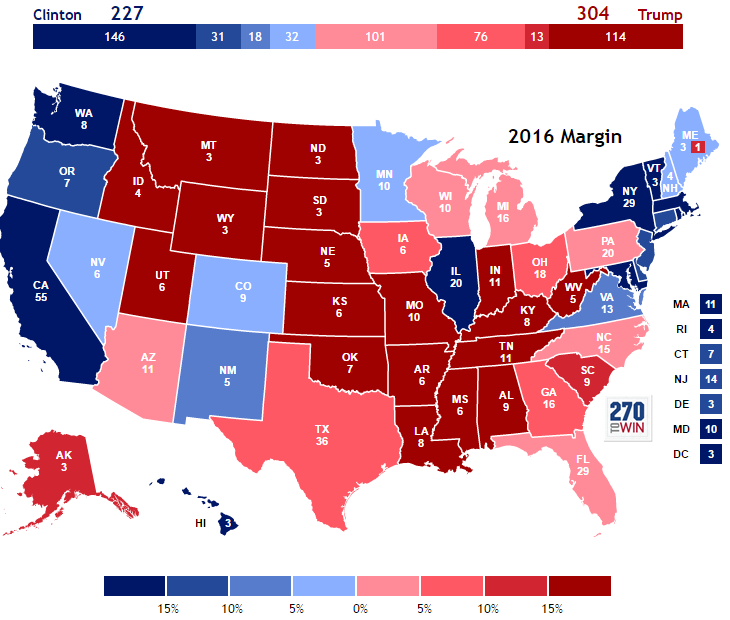
Atomistic Fallacy
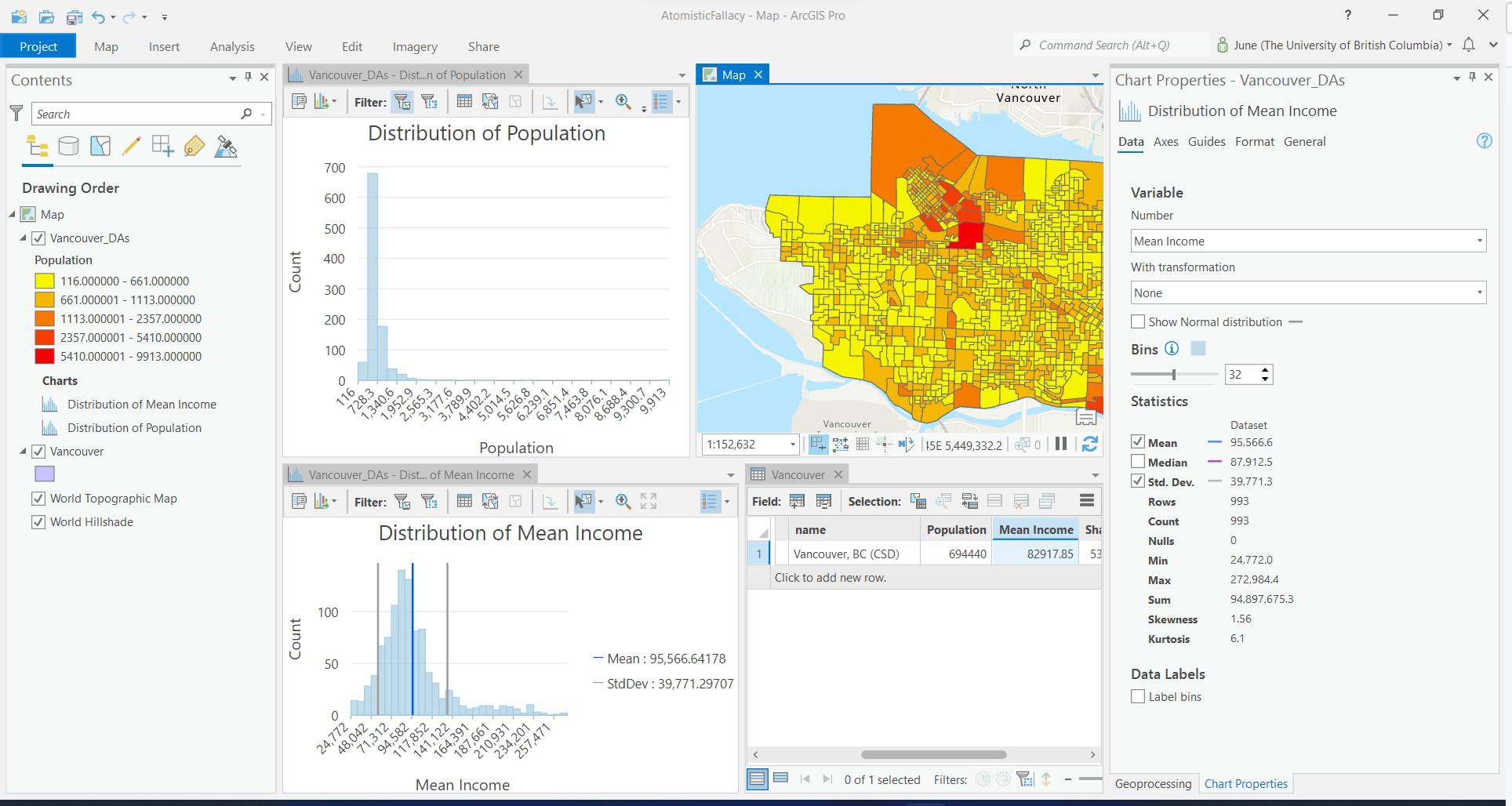
Atomistic Fallacy
The US Electoral College is an example of this in practice:
- Totaling votes per state … then totaling “delegates” by state.
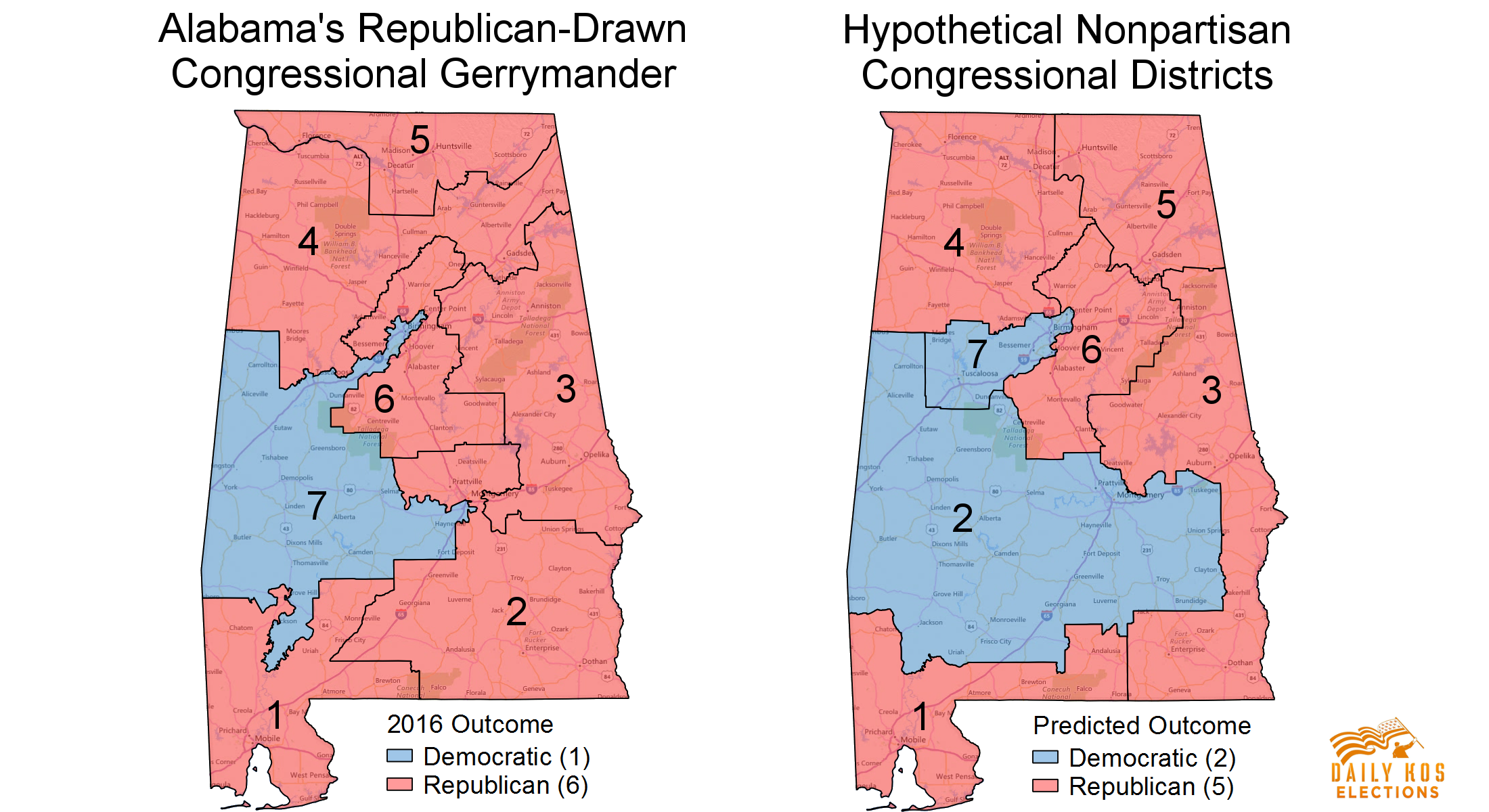
Modifiable Areal Unit Problem
Modifiable, arbitrary boundaries can have a significant impact on descriptive statistics for areas.
- When areas are grouped together, the way you choose to group them can change the values of the groups.
- See this video for more context.
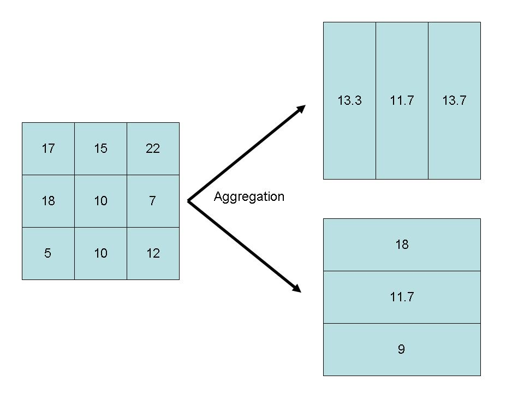
Modifiable Areal Unit Problem
Data collected at a finer level of detail is being combined into larger areas of lower detail that can be manipulated.
- Used to imply things that are not necessarily true.
- Serious ethical implications.
- Gerrymandering is a prime example.
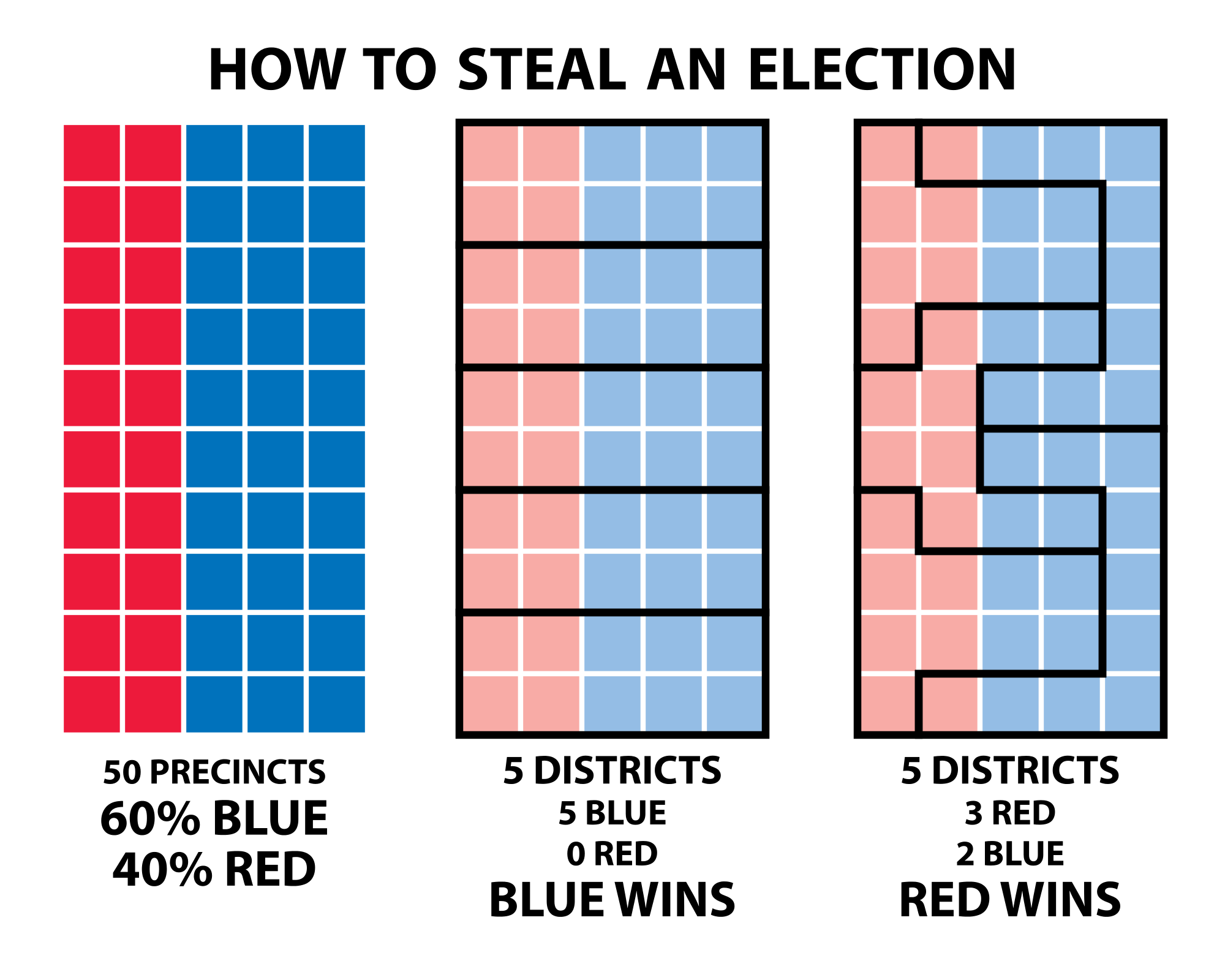
Modifiable Areal Unit Problem
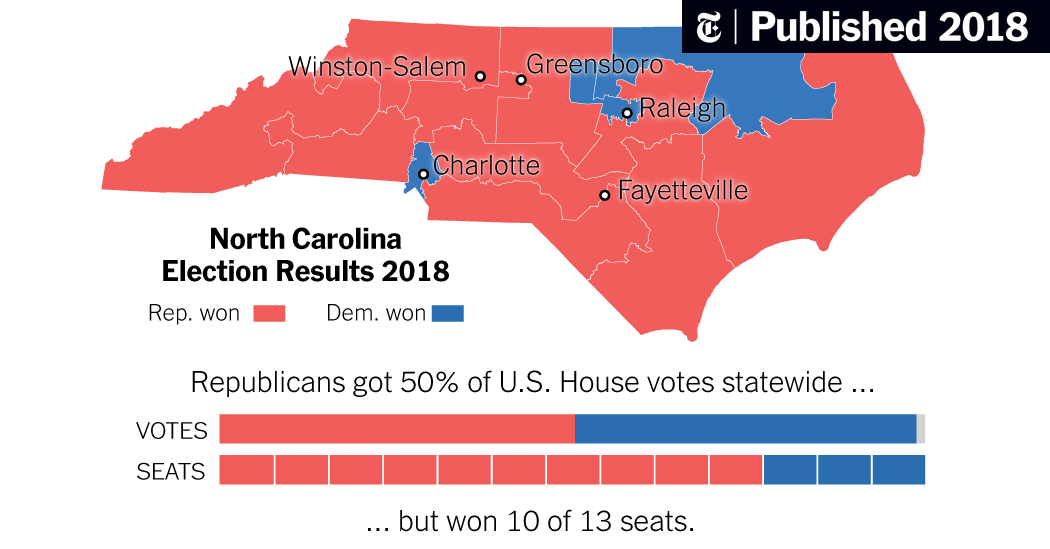
Modifiable Areal Unit Problem
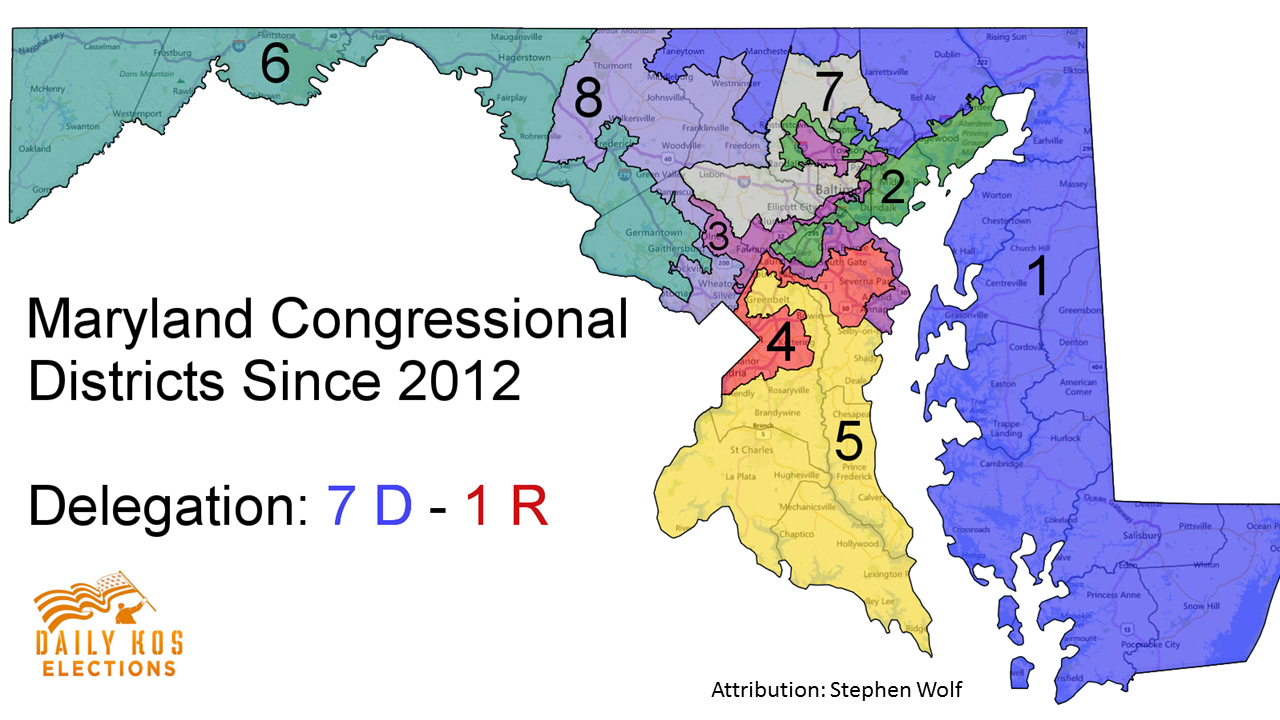
Modifiable Areal Unit Problem
Error Propagation
Errors are cumulative:
- Uncertainty will propagate through an analysis